As I've posted before, the Zelda series is my absolute favorite game series
(console game only) and Breath of the Wild (BotW) is my favorite game of all
time. I'm not saying the game was perfect, it definitely had it's share of
issues, but overall, the amount of joy I got from that game surpassed any other
game I've played.
So, of course I was super excited when the next Zelda game came out. Zelda:
Tears of the Kingdom (TotK).
Well… Sadly, so far, it's been a huge disappointment. I'm 60 hours into the
game. Was going to wait until I finished because maybe by the end I'll have
changed my mind. But then I though, no, I should write what I'm feeling now.
Regardless of how well it ends I've got lots of time in the game already and
want to record how I felt for 50 or so of the last 60 hours.
No Joy and Wonder of discovery
Probably the single biggest disappointment is TotK takes place in the same world
as BotW. I know lots of fans like that, but you can read
how disappointed I was with that in A Link Between Worlds.
Lots of people love that about both games. Me, it robbed me of the #1 joy I got
out of BotW, that is, discovering new places. Almost everywhere I go in TotK
I've already been there. The joy of discovery is removed. I remember playing
BotW and climbing a mountain and feeling wonder at seeing the spiral Rist
Peninsula. I remember seeing Eventide Island the first time and thing OMG! I can
go all the way over to that island!? I remember the joy I felt the first time I
crossed The Tabantha Great Bridge and saw how deep the canyon was. I remember
the first time I discovered the massive Forgotten Temple. And 30-50 other just
as "wow" and wondrous moments. The first time I saw a dragon. The first time
I saw a dragon up close. The first time it wasn't raining near Floria Bridge.
The first time I saw Skull Lake. The first time I saw Lomei Labyrinth Island.
The first time I saw Leviathan Bones. And on and on.
All of that joy is missing from TotK because I've already been to all of these
places. There's a few new places in the sky, but so far, none of them have been
impressive.
Building is both a great idea but also a chore
In TotK you can build things. They took the Magnesis power from BotW and added
that when you move one item next to another you can pick "Attach" and they'll
get glued together. The difference then is, in BotW you'd be near water that you
want to cross, you'd have to go find a raft. In TotK, you instead have to go
find parts. For example, find 3 logs or cut down 3 trees for 3 logs, then you
can glue the logs together, now you have a raft. It takes a couple of minutes to
build the raft. This makes TotK more tedious than BotW. I didn't really want to
build the raft, I just wanted to cross the river. Being able to build things is
a great idea but it's also unfortunately a chore. Maybe I'm not being creative
enough but mostly it's pretty obvious what to build and how to build it.
There is no guidance on direction
In BotW, after Link gets off the plateau, it's suggested he should go east. The
enemies and things encountered in that direction are designed for the beginning
player. Of course the player is free to go anywhere, but if they go in the order
suggested they'll likely get a better experience as enemies will be weaker,
shrines will have stuff that trains them. Etc...
In TotK, unless I missed it, no such direction happened. I ended up going to
Rito Village first because that was what some character in the game suggested.
30-40hrs in, I was going east from the center of Hyrule, and it's clear the
designers wished I'd gone that way first as the training shrines are all there.
Training you to use arrows, training you to parry, training you to throw
weapons, etc… It's possible I missed the hint but it feels like there was no guidance
suggesting I go that direction first.
Hitting Walls
I cleared 3 bosses (Rito, Goron, Zora) with no pants. Why? Because I never found
any source of money in the first 20-30 hours of play so all I could afford was
cold armor (500) and cold headgear (750). Pants cost (1000). Later I needed
flame guard armor and had to use all my money to buy just the top. I didn't have
enough money to buy pants, nor did I run into any source of money that far into
the game.
Here's my character, 60 hours into the game!

Another wall came up when I went to my 4th boss (Gerudo). The 2nd phase of the
boss way too hard. I quit the boss, went and made 25 meals for
hearts, and even then I could tell there was no way I was going to beat it when
12 or so fast moving Gibdos each take all of my hit points with 1 hit.
After dying too many times I finally gave in and checked online, the first time
I'd done so. According to what I read, my armor isn't up to the fight. Now I've spent
30+ hours trying to upgrade my armor but it's a super slog. I need to unlock all
of the fairies. Each one requires it's own side quest or 2. Once I've unlocked them I
have to go item hunting which will be another 10+ hours. I actually have money
now (~3000) and lots of gems but I know no where to buy good armor. I found the
fashion armor. I got some sticky armor. But I have yet to get any of my armor
upgraded more than 2 points past what it was 30 hours ago.
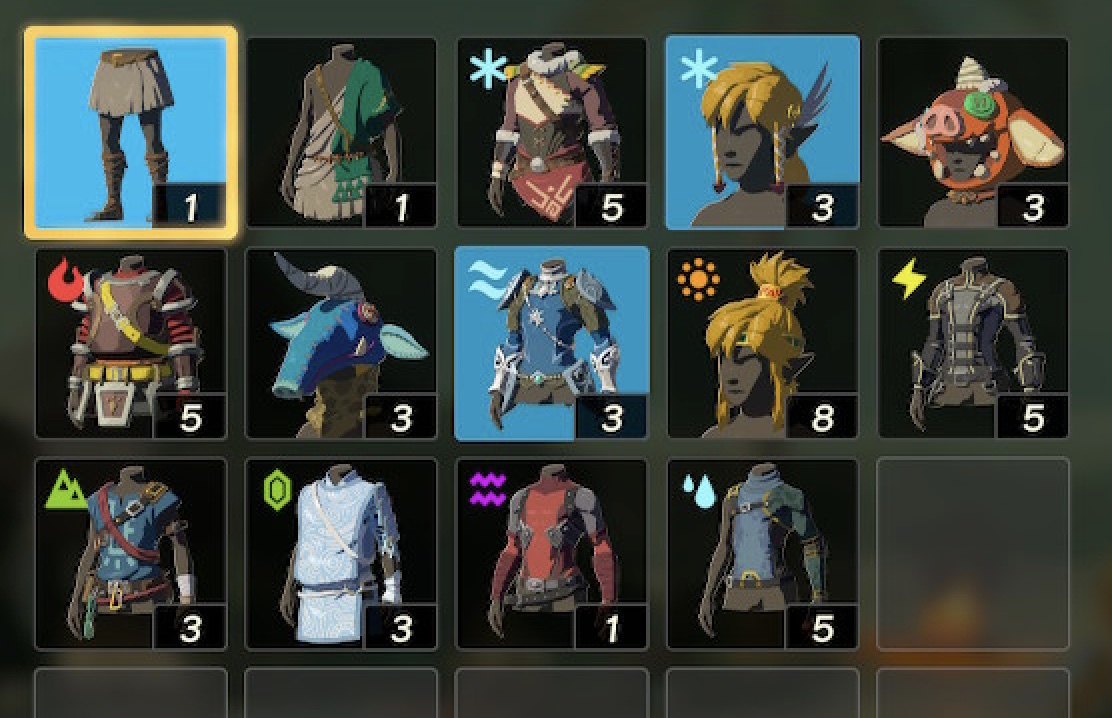
Fighting is still too hard (for me)
This is my collection of weapons 60hrs in!
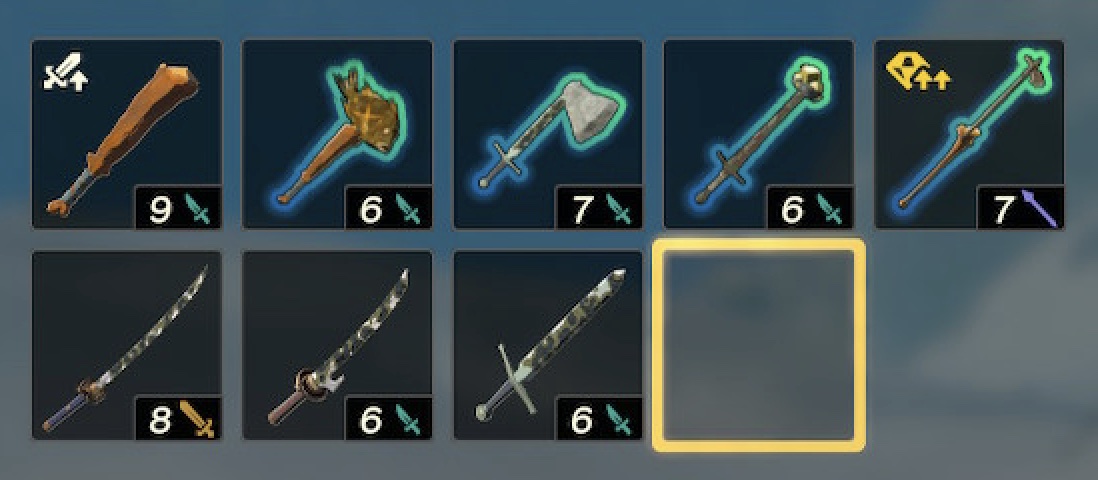
This is my collection of shields.

Where are the weapons!?!?!?!? The shield collections looks ok for 60hrs but
the weapons do not. Where are they?
I complained about the fighting in BotW. I found it not as fun as previous Zelda
games. Fighting in TotK hasn't changed so that's the same. I get that I suck at
it because I can watch videos of people who don't. But, for whatever reason,
unlike every other Zelda, I've never gotten the hang of fighting in either BotW
nor TotK. As such, I avoid fights as much as possible because basically the odds
of me dying are around 1 out of 3. Especially if the enemy is a Lizalfos. They
run fast, they take my weapon and/or shield leaving me defenseless.
Taking on a single enemy is something I can often handle but taking on 3 or more
I'm more often than not going to die.
I complained about this in BotW as well. I wish there was a combat trainer in
some village near the beginning of the game. He'd ask if you want to be trained
and you could pick yes or no. That way, people who hated the mandatory training
from previous Zelda games could skip it, but people like me, who want to train
in a place where you don't lose any hit points and never die, would have a place
to learn how to actually fight.
In BotW I basically avoided as many fights as I could and skipped all the
shrines with medium or hard tests of combat until after I'd finished the game.
In TotK it's been similar. I'm avoiding fights for the most part.
Surprisingly, in both games, the bosses (well most of them), were easy or
about the same level as previous Zelda games so it's super surprising that
combat from random monsters in the world is so friggen difficult.
The World of TotK is not Interesting
The world of TotK is not as interesting as BotW. Yes, it's the same map but
things have changed.
In BotW there were signs all over the world of ancient times, ruins, fields of
dead guardians, it felt epic. In TotK the world is covered with rubble from some
sky people's world falling down. For whatever reason, I'm not finding the TotK
world compelling.
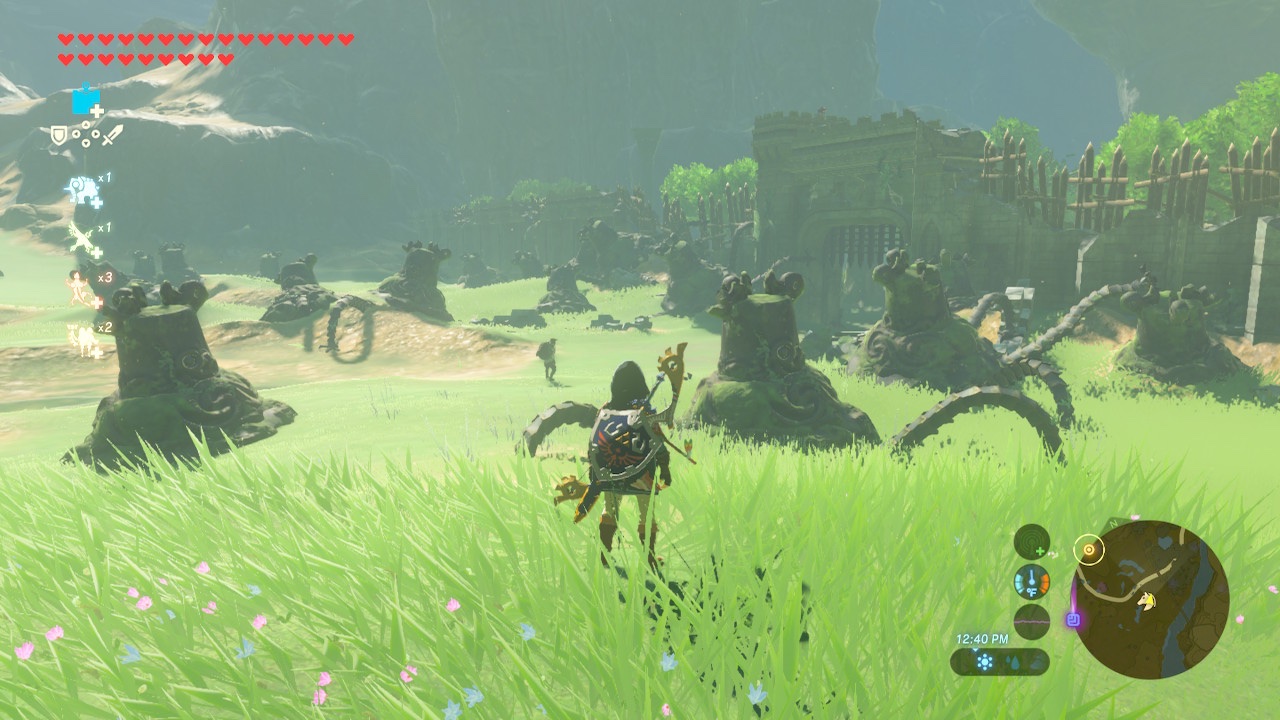
In BotW I'd come across a field of broken guardians next to a large thick stone
wall. It was clearly the site of an epic battle. Stuff all over BotW's world
suggests the place has history. Nothing in the world of TotK has made me wonder
anything at all. The idea of a Luputa like civilization in the sky is
interesting but nothing about the world presented in the sky in TotK suggests
anything interesting actually happened there. Instead it's all just stuff
designed around gameplay, not around what a civilization in the sky might be
like.
It was a mistake to use the same world as BotW in that there's no consistency.
Of course Zelda games have never been consistent but also, except for "A Link
Between Worlds" (which I was also disappointed with), no Zelda game has had
anything to do with any other Zelda game.
TotK though, because it's in the same world and because that world is so
detailed, it arguably needs more consistency. All of this talk of a world in the
sky that's always been there and is the source of the clean water in Zora's
Domain, etc does match BotW. The fact that all the old shrines are gone but have
magically been replaced by knew ones yet Kakariko Village and Hateno Village are
basically unchanged makes no sense. Of course, going from the first principle
(no Zelda's share anything) it doesn't matter. But, the fact that this Zelda is
the same world, Zelda even references Link saving Hyrule previously, means that
all those inconsistencies are highlighted. If they'd just made a new world that
would disappear.
Dark World
First off, what do these 6 pictures have in common?

Now look at this

During my first 60hrs, I saw the red gloom covered pits, always from a distance, always from ground level.
I thought I was supposed to avoid them! Especially because I thought they were the home of these

Those gloom hands are super scary. The screen changes color, the music gets super tense. As soon as I ran into one
I beamed out! So, I avoided these gloom covered holes for fear gloom hands would come out.
Some characters seemed to suggest I should check out some "chasms" and so I kept wondering when
I'd run into a chasm knowing that a chasm looks like those 6 examples above, not a pit/crater/hole.
In fact there are at last 4 chasms in BotW. Tanagar Canyon, Gerudo Canyon, Karusa Valley, Tempest Gulch.
All of those are chasms.
At the 60hr mark, I finally decided to check online, where could I find weapons.
The first post I found said, inside the "Hyrule Field Chasm" and marked it on the map.
I'm like WTF? There's a chasm there? I go look and find it just one of these pits, not
a chasm. So yea, because of poor localization or because the translator didn't bother to look up
what a chasm is, the "chasms" are mis-named. 🤬

I was kind pissed off I'd missed this for 60hrs (though I had been in the one from the Goron boss, which to be honest
was the only "wow" moment for me in the game so far). I was wondering when I'd find other entrances, especially
since someone gave me a map marking some spot in the dark far west from Death Mountain. Now I knew.
On the other hand, I was excited, hoping this was where I'd find the things I'd been missing.
Namely, discovering interesting places that filled me with wonder.
Well ... after 10hrs of exploring, no, the dark world doesn't provide what I was missing.
In fact, it's super boring!
I literally spent 6-7 hours just trying to find anything interesting, going from
lightroot to lightroot. This is what I opened
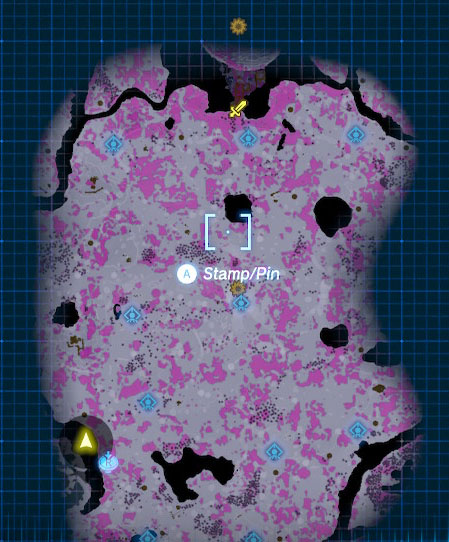
That entire area had nothing. 5 or so hours in I saw on the map there appeared to be
something of interest at the far north but I couldn't find a way to access it. I tried
diving into the pit under Hyrule Castle but I didn't find a way to the stuff on the
map, even though it marked me as just north of it. I eventually gave up on that.
I eventually found some stairs with flames and was hoping it was a temple or dungeon.
No, it was just a place to use "Ascend" and deposited me on a tower at the Bridge of Hylia.
At the 6-7 hour point I finally found "Autobuild" and thought
maybe that would open something new. Nope. The characters that gave it to me pointed some
direction that led to some mine carts. I explored them but found nothing.
I spent another couple of hours opening more lightroots and still nothing.
This includes an hour or so of "grinding" since I ran out of arrows and
all of my bows broke from shooting giant brightbloom seeds. I know Zelda
has always had some amount of grind but it feels worse in TotK, probably
because I'm not enjoying the game. First I needed to go get money, then
I needed to buy arrows, then I need to find bows. So yea, about an hour.
The dark hasn't saved TotK for me, in fact it's had the opposite effect.
I like it even less given how boring the dark has been. It's like some
bad filler content.
TotK has bad writing
Zelda games have never had a ton of story. They're all about the game play.
But, TotK has the worst so far. Let me put that another way, TotK has an
interesting story premise. It's just that individual parts make no sense.
In one scene, Ganondorf appears and magically stabs someone in the back. The
fact that he could do that invalidates all his other actions and the rest of the
story. If he can just magically kill anyone then he should have killed Zelda and
the King and everyone who stands in his way.
The scene where the Queen says Zelda is hiding that she wants to help is some of
the most silly childish writing ever.
The scene where Ganondorf appears before King Raura, Queen Sonia and Zelda
pledging allegiance, doesn't seem like it makes any sense, Zelda is from the
future and knows who Ganondorf is, so her reaction to seeing him (not sure she
trusts him), makes no sense. She knows exactly who he is.
Good things of TotK
Things I like about TotK.
Recipes
I still find cooking tedious. I don't hate it. But it is annoying to
have to take 5-10 minutes cooking for a big battle. In BotW you had
to just memoize the recipes. In TotK it memorizes them for you.
Unfortunately I found them mostly useless. For whatever reason, I remember
rarely not having the ingredients to make good recipes in BotW. In TotK
it feels like I rarely have the right ingredients. I click on some ingredient
and look at what recipes it can be used in and I never have everything needed.
Maybe the fact that I have recipes memorized for me just ends up pointing
out what I don't have more than BotW. I don't know what changed, all I know
is I have very few good meals.
Ascend
One of my favorite features of BotW is how open the world is because
you can climb almost anything. It was a big departure from most other
games where you're stuck behind various barriers.
That said, it was often a little slow to climb a large mountain.
In TotK you get the "Ascend" power, which lets you swim vertically through
things. With this ability, and the fact that the world is littered with
parts that fell from the sky, many mountains that were slow to climb now
have areas where you get can under one of these fallen sky parts and
beam yourself through them. This makes climbing things slightly less slow
and a little more fun.
Of course it also opens up a bunch of interesting puzzles.
Fuze
I'm a little mixed on fuze. I think it's interesting that you can
upgrade your weapons, your shields, and your arrows, in like 50+
ways each. Put a flame emitter on your shield and it emits flames
anytime you put up your shield. Put a lightning emitter on the end
of a staff and you can electrify anything it touches. Put a rock
on the end of a log and you have something that can crush rocks.
On the other hand, with arrows, you no longer have a supply of types
of arrows. In previous Zelda games, you'd have, separately, normal arrows,
fire arrows, freeze arrows, bomb arrows, electric arrows. So you could
collect say, 50 fire arrows and shoot them fast.
In TotK you only have regular arrows and on each shot you can pause
the game and for this one single shot, fuze something to the arrow.
Fuze a flame fruit and you get a fire arrow.
The variety is good. I feel like I'm almost never out of fire arrows.
Plus you can fuze other things like Keese Eyes that give you homing
arrows. On the other hand, shooting arrows is now tedious and
interrupts the combat because every single shot you pause the game and
pick from a list of 200+ items.
Vehicles
IIRC, BotW didn't have many vehicles. There was a bonus one from the DLC
but otherwise I don't remember any. I guess the Goron mine carts?
In TotK there are a few. Floating platforms, gliders, wheeled platforms,
and more. They've been both interesting and so far kind of feel like an
after thought.
I like that they exist but, 60 hours in, there's only been
a few places where they were actually needed.
Disappointing
I've thought about quitting and not finishing TotK. That's a first for
me in a Zelda game. Again, it's my favorite video game series. The only
amiibo I own is a BotW guardian.

I have Zelda fan art posters on my walls

I even have Zelda key chains

and Zelda coasters

In other words, I'm a huge Zelda fan, not a hater.
It's really disappointing to find I'm not enjoying TotK as much as I had
hoped.
At 70hrs, which is probably the 3rd most I've played any game ever (BotW being #1), I think I'm done.
I want to see the end but I'm sick of just grinding, trying to find armor so I can survive a boss fight.
I can go dive in some other pit but if it's just more grinding from lightroot to lightroot what's
the point?
Thoughts after finishing 15 days after I wrote the stuff above.
According to my profile I "Played for 105 hours or more" so that's 35 hours more than when I wrote
my thoughts above. Those 35 hours felt like another 70 and I'm actually surprised it claims
only 105 hours given it's been two weeks but whatever 🤷♂️
Dark World
So, apparently I didn't need to check the "chasms". Some time after I got the Master Sword,
a character told me to follow him down one of the "chasms" and that led to the things you're
supposed to do down there. In other words, the 10 hours I spent trying to find anything
down there were mostly pointless and my experience would have been better if I'd not looked
online and not followed the advice to go into into a "chasm".
Still, I did feel like the dark world is mostly filler. Unlike the world above which has
snow areas, mountain areas, forests, jungles, beaches, clifts, deserts, etc... The dark
world is pretty much the same all over. Once the characters told me what to do down
there it wasn't nearly as tedious although I'd already lit up many of the places they
directed me to go.
Mineru
Mineru's addition seemed wasted, or else I didn't figure out how to use it.
For something so late in the game with so much flexibility, it seemed like it
might add lots of new and interesting gameplay, but in the end I mostly ignored
it. I'll have to go online to see what I missed I guess.
The Story
While I had lots of issues with the details in the story and how much of it didn't
make any sense, including Ganondorf's last act, I did end up enjoying Zelda's
arc. That part was good.
Too Hard
I still found it too hard. I spent I think literally a week or more trying to beat
Ganondorf in the last boss fight.
First, after a few tries, it was clear to me I didn't have enough of the right
meals to survive so I beamed out. That means you have to start the entire
sequence over, fight your way into the boss area, go through 5 waves of
Ganondorf summoning swarms of enemies, before you can get back to the main
fight. The whole thing felt so tedious to me, spending several hours getting the
right ingredients to make the types of meals needed to survive and getting the
gloom resistant armor and upgrading it. I only managed to upgrade it once per
piece as looking at the requirements for twice would have easily required
another 3-5 hours of nothing but battles with giant gloom monsters in the dark
🙄
One you're actually fighting Ganondorf you're required to Flurry Rush him which
you can only do after you execute a Perfect Parry or Perfect Dodge. Again I'm
going to complain that I wish there was a place you could choose to train that
was like older Zelda games where some teacher would tell you exactly when to do
the move and not let you out until you'd done it several times but at the same
time actually let you practice quickly.
As it was, I had to learn by fighting Ganondorf 60+ times and it felt like ass
to wait for the death screen, wait for the reload, etc. After a few times I'd get
frustrated, feel like throwing my controller through my TV, and so quit the game
and wait a few hours or the next day to try again. Worse, in Ganondorf's 3rd
phase, you have to Perfect Parry/Dodge twice in a row and I could rarely do it.
In the final battle where I beat him, I made it through the first two phases
without taking a single hit. In other words, I'd learned to correctly Perfect
Dodge. But, on the 3rd phase it was still super frustrating I couldn't do it in
this phase and he'd hit me 4 out of 5 times and only 1 out of 5 would be able to
do the double Perfect Dodge. Even a single Perfect Dodge was hard. The point
being I needed a place to train so that this battle felt good. I never felt like
I was doing it wrong since I was doing it exactly the same as the previous two
phases. Rather, I felt like the game wasn't making it clear what I was suppose
to be doing. When I managed to pull off a Perfect Dodge it just felt like luck
as to me it felt like I was pushing the buttons at the same time every
time.
Building
Once I'd beaten the game I went back in to check a few things I still had
marked on the map. I checked out a couple of sky places I'd never been
to and for one, the only way I could see to get to the top was to build
a flying machine.
Watching some videos it's clear I
missed quite a few interesting things I could maybe have built? On the other
hand, many of them are things that don't interest me. I had this same issue in
BotW. There wasn't building but there was physics in BotW and watching videos of
creative ways I could attack groups of outdoor enemies using these techniques
was interesting. The thing is, I didn't want to fight the enemies, I wanted to
"continue the adventure" so taking the time to setup some special way of
attacking enemies just felt like a waste of time. I'm not saying others
shouldn't enjoy that activity. Only that I didn't enjoy it. My goal wasn't to
fight as many enemies as possible, it was to go to the next goal, discover the
next interesting place, advance the story. Except for bosses and enemies in
dungeons, the outdoor enemies are just things in the way of what I actually want
to do.
There's some crazy contraptions people built in that video above. It's just that
building those contraptions doesn't advance me toward completing the game.
Final Thoughts.
It's hard for me to say what I'd feel if I'd never played BotW and only
played TotK. I still feel like BotW is a better game even though in way
TotK is all of BotW plus more.
I think the issue for me is, BotW was all about discovering the various
areas of Hyrule. For me, discovering each area was 60-70% of the joy I got.
If I'd never played BotW, maybe I would have enjoyed TotK more, but,
the game feels designed for people that played BotW. I feel like BotW
was designed to get you to explore the world, by which I mean, based on
what the characters you meet tell you, you end up wanting to go to each
place. In TotK I feel like that's less true. It's hard to say if that
feeling is real or it's only because I've been to all these places already
in BotW.
Partly it's that TotK is 1.8x larger than BotW so if they'd directed you
to explore all of the BotW parts the game would be way too long. Instead they
mostly just direct you to visit some parts plus much of the new stuff
and leave the rest as random playground.
In any case, BotW is still my favorite Zelda and TotK, while it had a
few great highlights, is much further down the list if was to rank
every Zelda.
Here's hoping the next one is an entirely new world.