I recently made 2 new sites. They came about like this.
Once in a while I want to benchmark solutions in JavaScript just to see how much slower one solution is vs another. I used to use jsperf.com but sometime in early 2020 or 2019 it disappeared.
Searching around I found 2 others, jsbench.me. Trying them they both have their issues. Jsbench.me is ugly. Probably not fair but whatever. Using it bugged me. Jsben.ch, at least as of this writing had 2 issues when I tried to use it. One is that if my code had a bug the site would crash as in it would put up a full window UI that blocks everything with a "running..." message and then never recovers. The result was all the code I typed in was lost and I'd have to start over. The other is it has a 4k limit. 4k might sound like a lot but I ran into that limit trying to test a fairly simple thing. I managed to squeeze my test in with some work but worse, there's no contact info anywhere except a donate button that leads directly to the donation site, not a contact sight so there's no way to even file a bug let alone make a suggestion.
In any case I put up with it for 6 months or so but then one day about a month ago, I don't remember what triggered it but I figured I could make my own site fairly quickly where I'm sure in my head quickly meant 1-3 days max. 😂
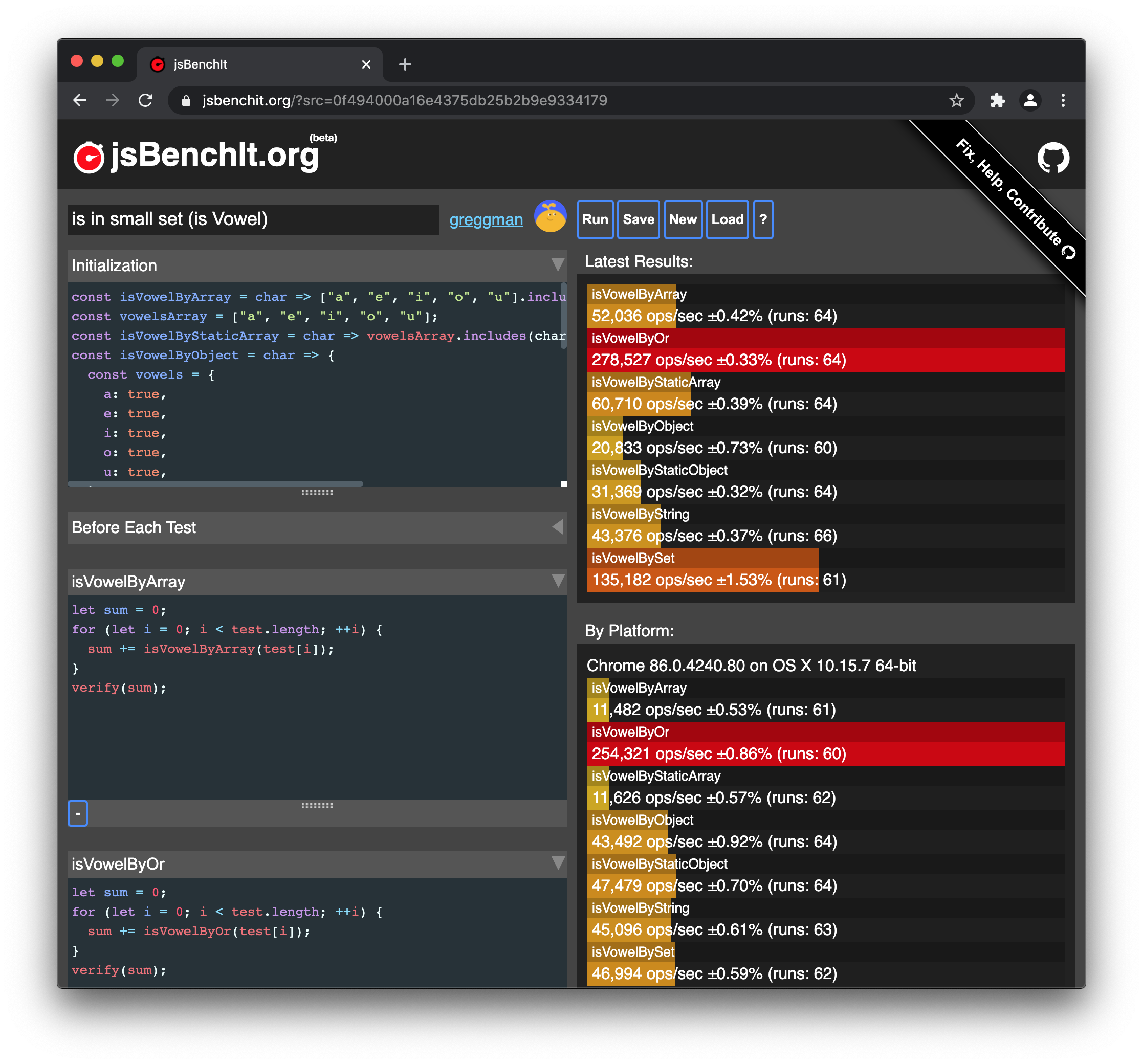
benchmark.js
So, this is what happened. First I decide I should use benchmark.js mostly because I suck at math and it claims "statistically significant results". I have no idea what that means 😅 but, a glance at the code shows some math happening that's more than I'd do if I just wrote my own timing functions.
Unfortunately I'd argue benchmark.js is actually not a very good library. They made up some username or org name called "bestiejs" to make it sound like it's good and they claim tests and docs but the docs are horrible auto-generated docs. They don't actually cover how to use the library they just list a bunch of classes and methods and it's left to you to figure out which functions to call and when and why. There's also some very questionable design choices like the way you add setup code is by manually patching the prototype of one of their classes. WAT?!?
I thought about writing my own anyway and trying to extract the math parts but eventually I got things working enough and just wanted to move on.
Personal Access Tokens
I also didn't want to run a full server with database and everything else so I decided I'd see if it was possible to store the data in a github gist. It turns out yes, it's possible but I also learned there is no way to make a static website that supports Oauth to let the user login to github.
A workaround is a user can make a Personal Access Token which is a fancy way of basically making a special password that is given certain permissions. So, in order to save the user would have to go to github, manually make a personal access token, paste it into jsbenchit.org and then they could save. It worked! 🎉
As I got it working I released I could also make a site similar to jsfiddle or codepen with only minor tweaks to the UI so I started on that too.
¯\(ツ)/¯
Running User Code
Both sites run arbitrary user code and so if I didn't do something people could write code that steals the personal access token. That's no good. Stealing their own token is not an issue but passing a benchmark or jsgist to another user would let them steal that user's token.
The solution is to run the user's code in an iframe on another domain. That domain can't read any of the data from the main site so problem is solved.
Unfortunately I ran into a new problem. Well, maybe it's not so new. The problem is since the servers are static I can't serve the user's code like a normal site would. If you look at jsfiddle, codepen, and stack overflow snippets you'll see they run the code from a server served page generated using the user's code. With a static site I don't have that option.
To work around it I generated a blob, make a URL to the blob and have the browser load that in an iframe. I use this solution on webgfundmentals.org, webgl2fundamentals.org, and threejsfundamentals.org It works but it has other problems. One is since I can't serve any files whatsoever I have to re-write URLs if you use more than 1 file.
Take for example something that uses workers. You usually need a minimum of 2 files. An HTML file
with a <script> section that launches a worker and the worker's script is in another file.
So you start with main.html that loads worker.js but you end up with blob:1234-1314523-1232
for main.html but it's still referencing worker.js and you have to some how find that and
change it to the blob url that was generated for worker.js. I actually implemented this solution on
those sites I mentioned above but it only works because I wrote all the examples that are running
live and the solutions only handle the small number of cases I needed to work.
The second problem with the blob solution they are no good for debugging. Every time the user clicks "run" new blobs are created so any breakpoints you set last time you ran it don't apply to the new blob since they're associated with a URL and that URL has just changed.
Looking into it I found out I could solve both problems with a service worker. The main page starts the service worker then injects the filename/content of each file into the service worker. It then references those files as normal URLs so the don't change. Both problems are solved. 😊
I went on to continue making the sites even though I was way past the amount of time I thought I'd be spending on them.
Github Login
In using the sites I ran into a new problems. Using a personal access token sucked! I have at least 4 computers I want to run these on. A Windows PC, a Mac, an iPhone, and an Android phone. When I'd try to use a different PC I needed to either go through the process of making a new personal access token, or I needed to find someway to pass that token between machines, like email it to myself. 🤮
I wondered if I could get the browser to save it as a password. It turns out, yes,
if you use a <form> and an <input type="password"> and you apply the correct
incantation when the user clicks a "submit" button the browser will offer to save
the personal access token as a password.
Problem solved? No 😭
A minor issue is there's no username but the browsers assume it's always username + password. That's not that big a deal, I can supply a fake username though it will probably confuse users.
A major issue though is that passing between machines via a browser's password manager doesn't help pass between different browsers. If I want to test Firefox vs Chrome vs Safari then I was back to the same problem of keeping track of a personal access token somewhere.
Now I was entering sunk cost issues. I'd spent a bunch of time getting this far but the personal access token issues seemed like they'd likely make no one use either site. If no one is going to use it then I've wasted all the time I put in already.
Looking into it more it turns out the amount of "server" need to support oauth so that users could log in with github directly is actually really tiny. No storage is needed, almost nothing.
Basically they way Oauth works is
- user clicks "login with github"
- static page opens a popup to
https://github.com/login/oauth/authorizeand passes it an app id (called client_id), the permissions the app wants, and something called "state" which you make up. - The popup shows github's login and asks for permission for the app to use whatever features it requested.
- If the user picks "permission granted" then the github page redirects
to some page you pre-registered when you registered your app with github.
For our case this would be
https://jsbenchit.org/auth.html. To this page the redirect includes a "code" and the "state" passed at step 2. The
auth.htmlpage either directly or by communicating with the page that opened the popup, first verifies that the "state" matches what was sent at step 2. If not something is fishy, abort. Otherwise it needs to contact github at a special URL and pass the "code", the "client_id" and a "client_secret".Here's the part that needs a server. The page can't send the secret because then anyone could read the secret. So, the secret needs to be on a server. So,
- The page needs to contact a server you control that contains the secret and passes it the "code". That server then contacts github, passes the "code", "client_id", and "client_secret" to github. In response github will return an access token which is exactly the same as a "personal access token" except the process for getting one is more automated.
- The page gets the access token from the server and starts using it to access github's API
If you were able to follow that the short part is you need a server, and all it has to do is given a "code", contact github, pass the "code", "client_id" and "client_secret" on to github, and pass back the resulting token.
Pretty simple. Once that's done the server is no longer needed. The client will function without contacting that server until and unless the token expires. This means that server can be stateless and basically only takes a few lines of code to run.
A found a couple of solutions. One is called Pizzly. It's overkill for my needs. It's a server that provides the oauth server in step 6 above but it also tracks the tokens for you and proxies all other github requests, or requests to whatever service you're using. So your client side code just gets a pizzly user id which gets translated for you to the correct token.
I'm sure that's a great solution but it would mean paying for a much larger server, having to back up user accounts, keep applying patches as security issues are found. It also means paying for all bandwidth between the browser can github because pizzly is in the middle.
Another repo though made it clear how simple the issue can be solved. It's this github-secret-keeper repo. It runs a few line node server. I ran the free example on heroku and it works! But, I didn't want to make an heroku account. It seemed too expensive for what I needed it for. I also didn't feel like setting up a new dynamo at Digital Ocean and paying $5 a month just to run this simple server that I'd have to maintain.
AWS Lambda
I ended up making an AWS Lambda function to do this which added another 3 days or so to try to learn enough AWS to get it done.
I want to say the experience was rather poor IMO. Here's the problem. All the examples I found showed lambda doing node.js like stuff, accepting a request, reading the parameters, and returning a response. Some showed the parameters already parsed and the response being structured. Trying that didn't work and it turns out the reason is AWS for this feature is split into 2 parts.
Part 1 is AWS Lambda which just runs functions in node.js or python or Java etc...
Part 2 is AWS API Gateway which provides public facing endpoints (URLS) and routes them to different services on AWS, AWS Lambda being one of those targets.
It turns out the default in AWS API Gateway doesn't match any of the examples I saw. In particular the default in AWS API Gateway is that you setup a ton of rules to parse and validate requests and parameters and only if they parse correctly and pass all the validation do they get forwarded to the next service. But that's not really what the example shown wanted. Instead they wanted AWS API Gateway to effectively just pass through the request. That's not the default and I'd argue it not being the default is a mistake.
My guess is that service was originally written in Java. Because Java is strongly typed it was natural to think in terms of making the request fit strong types. Node.js on the other hand, is loosely typed. It's trivial to take random JSON, look at the data you care about, ignore the rest, and move on with your life.
In any case I finally figured out how to get AWS API Gateway to do what all the AWS Lambda examples I was seeing needed and it started working.
My solution is here if you want to use it for github or any Oauth service.
CSS and Splitting
Next up was spitting and CSS. I still can't claim to be a CSS guru in any way shape or form and several times I year I run into infuriating CSS issues where I thought I'd get something done in 15 minutes but turns into 15 minutes of the work I thought I was going to do and 1 to 4 hours of trying to figure out why my CSS is not working.
I think there are 2 big issues.
is that Safari doesn't match Chrome and Firefox so you get something working only to find it doesn't work on Safari
Nowhere does it seem to be documented how to make children always fill their parents. This is especially important if you're trying to make a page that acts more like an app where the data available should always fit on the screen vs a webpage that be been as tall as all the content.
To be more clear you try (or I try) to make some layout like
+--------------------+ | | +---+------------+---+ | | | | | | | | | | | | +---+-----+------+---+ | | | +---------+----------+
and I want the entire thing to fill the screen and the contents of each area expand to use all of it. For whatever reason it never "just works". I'd think this would be trivial but something about it is not or at least not for me. It's always a bunch of sitting in the dev tools and adding random
height: 100%ormin-height: 0orflex: 1 1 auto;orposition: relativeto various places in the hope things get fixed and they don't break something else or one of the other browsers. I'd think this would be common enough that the solution would be well documented on MDN or CSS Tricks or some place but it's not or at least I've never found it. Instead there's just all us clueless users reading the guesses of other clueless users sharing their magic solutions on Stack Overflow.I often wonder if any of the browser makers or spec writers ever actually use the stuff they make and why they don't work harder to spread the solutions.
Any any case my CSS seems to be doing what I want at the moment
That said, I also ran into the issue that I needed a splitter control that let you drag the divider between two areas to adjust their sizes. There's 3 I found but they all had issues. One was out of date, and unmaintained and got errors with current React. Yea, I used react. Maybe that was a bad decision. Still not sure.
After fighting with the other solutions I ended up writing my own so that was a couple of days of working through issues.
Disqus
Next up was comments. I don't know why I felt compelled to add comments but I did. I felt like people being able to comment would be net positive. Codepen allows comments. The easiest thing to do is just tack on disqus. Similar to the user code issue though I can't use disqus directly on the main site otherwise they could steal the access token.
So, setup another domain, put disqus in an iframe. The truth is disqus already puts itself in an iframe but at the top level it does this with a script on your main page which means they can steal secrets if they want. So, yea, 3rd domain (2nd was for user code).
The next problem is there is no way in the browser to size an iframe to fit its content. It seems ridiculous to have that limitation in 2020 but it's still there. The solution is the iframe sends messages to the parent saying what size its content is and then the parent can adjust the size of the iframe to match. It turns out this is how disqus itself works. The script it uses to insert an iframe listens for messages to resize the iframe.
Since I was doing iframe in iframe I needed to re-implement that solution.
It worked, problem solved..... or is it? 😆
Github Comments
It's a common topic on tech sites but there is a vocal minority that really dislike disqus. I assume it's because they are being tracked across the net. One half solution is you put a click through so that by default disqus doesn't load but the user can click "load comments" which is effectively an opt in to being tracked.
The thing is, gists already support comments. If only there was a way to use them easily on a 3rd party site like disqus. There isn't so, ....
There's an API where you can get the comments for a gist. You then have to format them from markdown into HTML. You need to sanitize them because it's user data and you don't want people to be able to insert JavaScript. I was already running comments on a 3rd domain so at least that part is already covered.
In any case it wasn't too much work to get existing comments displayed. New comments was more work though.
Github gists display as follows
+----------+ | header | +----------+ | files | | | | | +----------+ | comments | | | | | +----------+ | new | | comment | | form | +----------+
that comment form is way down the page. If there was an id to jump to I could have possibly
put that page in an iframe and just use a link like https://gist.github.com/<id>/#new-comment-form.
to get the form to appear in a useful way. That would give the full github comment UI which
includes drag and drop image attachments amount other things. Even if putting it in an iframe
sucked I could have just had a link in the form of
<a href="https://gist.github.com/<id>/#new-comment-form">click here to leave a comment</a>
But, no such ID exits, nor does any standalone new comment form page.
So, I ended up adding a form. But for a preview we're back to the problem of user data on a page that has access to a github token.
The solution to put the preview on a separate page served from the comments domain and send a message with new content when the user asks for a preview. That way, even if we fail to fully sanitize the user content can't steal the tokens.
Embedding
Both sites support embedding
jsgist.org just uses iframes.
JsBenchIt supports 2 embed modes. One, uses an iframe.
+ there's no security issues (like I can't see any data on whatever site you embedded it)
- It's up to you to make your iframe fit the results
The other mode uses a script
+ it can auto size the frame
- if I was bad I could change the script and steal your login credentials for whatever site you embed it on.
Of course I'd never do that but just to be aware. Maybe someone hacks my account or steals my domain etc... This same problem exists for any scripts you use from a site you don't control like query from a CDN for example so it's not uncommon to use a script. Just pointing out the trade off.
I'm not sure what the point of embedding the benchmarks is but I guess you could show off your special solution or, show how some other solution is slow, or maybe post one and encourage others to try to beat it.
Closing Thoughts
I spent about a month, 6 to 12hrs a day on these 2 sites so far. There's a long list of things I could add, especially to jsgist.org. No idea if I will add those things. jsbenchit.org has a point for me because I didn't like the existing solution. jsgist.org has much less of a point because are are 10 or sites that already do something like this in various ways. jsfiddle, codepen, jsbin, codesandbox, glitch, github codespaces, plunkr, and I know there are others so I'm not sure what the point was. It started as just a kind of "oh, yea, I could do that too" while making jsbenchit and honestly I spent probably spent 2/3rds of the time there vs the benchmark site.
I honestly wish I'd find a way to spend this kind of time on something that has some hope of generating income, not just income but also something I'm truly passionate about. Much of this feels more like the procrastination project that one does to avoid doing the thing they should really do.
That said, the sites are live, they seem to kind of work though I'm sure there are still lurking bugs. Being stored in gists the data is yours. There is no tracking on the site. The sites are also open source so pull requests welcome.